This article launches a series documenting a practical experiment: can an LLM, guided by clear requirements and prompts, design and scaffold a complete application while the human remains primarily a product owner? I’ll share outcomes, constraints, and what it really takes to hand the keyboard to AI—without debating the value of developers. The aim is speed, clarity, and process.
Purpose and Scope
Objective: Assess how quickly and effectively an LLM (via Abacus.AI) can implement a complete workflow from a well-structured requirements document.
Scope: Build a LangGraph pipeline to:
Read a CSV of URLs
Analyze each with Google PageSpeed Insights (mobile and desktop)
Export results to CSV
Update HubSpot via API/Custom App integration
Non-goal: This experiment does not attempt to prove or disprove the role of humans in software development.
Why This Approach
Over the past few months, I’ve explored LLMs as active builders, not just assistants. For this first installment, I provided Abacus.AI with a Project Requirements Document (PRD) and asked it to:
Propose a script creation order
Generate a directory structure and code stubs
Package each phase as its own zip
Suggest dependencies and environment setupI also wrote about the importance of upfront planning; if you’re curious about that philosophy, see: https://aragrow.me/blog/general-and-president-dwight-d-eisenhower-said-it-best/
The Requirements in Brief
Build a LangGraph workflow with nodes for: URL import/validation; PageSpeed API loop; data parsing; Gemini-based analysis; CSV export; HubSpot updates.
Use Google PageSpeed Insights, Google Gemini, and HubSpot APIs.
Employ solid engineering practices: dependency injection, type hints, structured logging, retries, test scaffolding, and environment-based configuration.
Success criteria: Process 100+ URLs, ≥95% PageSpeed call success, accurate CSV reporting, successful HubSpot updates, graceful error handling, and complete 100 URLs in under 5 minutes.Method: How I Prompted the LLM
Planning input: I provided the Project Requirement Document (PRD) as the system of record.
Packaging request: “Create a zip file with the directory structure and files (imports + class definitions only).”
Dependency guidance: I would add in next try, “Check that suggested packages are not deprecated and use current versions.”
Phased generation: I requested eight separate zips, one per phase:
Foundation (utils + config)
Models (data structures)
Services (API clients)
Nodes (workflow steps)
Workflow assembly (LangGraph)
Entrypoint (main.py)
.env generation
Validation & testing
Installation guidance: I asked for the recommended unzip/install order.
What Worked Well
The LLM produced a directory structure, class stubs, and requirements closely aligned to the PRD.
The recommended script creation order was accurate and practical.
The multi-zip approach reduced scope creep and made it easier to validate each phase.Where It Needed Adjustment
Dependencies: A few suggested packages were deprecated; adding an explicit “use current, non-deprecated packages” instruction could help.
Naming consistency: Some class, method, and variable names drifted across phases. This is manageable but worth noting if you plan to automate assembly.Time and Effort
Planning the PRD: ~1 hour
Generating the eight zip files: ~1 hour
Setting up the app: ~1 hour
Troubleshooting and completing the workflow: ~9 hours
Mid-experiment change to I/O handling: ~2 hours (included in the 9)
Total: ~12 hours to achieve batch URL analysis and prepare for HubSpot updates
Note: I generated the HubSpot update call but did not execute it on production data.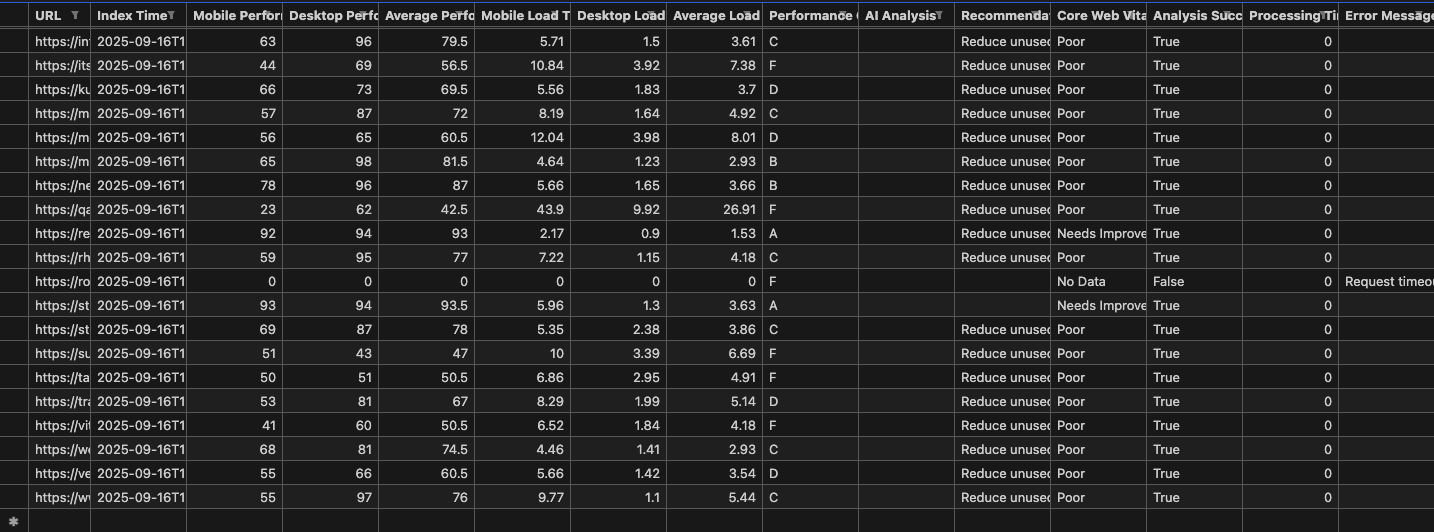
Lessons Learned
A strong PRD is a force multiplier. Clarity in inputs, outputs, models, and success criteria reduces hallucinations and rework.
Request current, non-deprecated dependencies explicitly.
Phase your code generation. Smaller, testable increments produce better outcomes and make inconsistencies easier to catch.
Expect light refactoring for naming consistency across independently generated phases.Recommendations for Others
Include precise API endpoints, data schemas, and rate-limit strategies in your PRD.
Specify package versions or ask the model to verify current stable releases.
Enforce naming conventions in prompts (e.g., “Use PascalCase for classes, snake_case for methods/variables; do not rename between phases”).
Automate linting and type checks early (ruff/mypy/pytest stubs) to catch drift quickly.What’s Next in the Series
Next, I’ll modify the PRD and provide more detailed instructions to tighten automated checks to reduce human intervention further. The goal remains the same: give the AI clear instructions—and see how far it can go.